Method
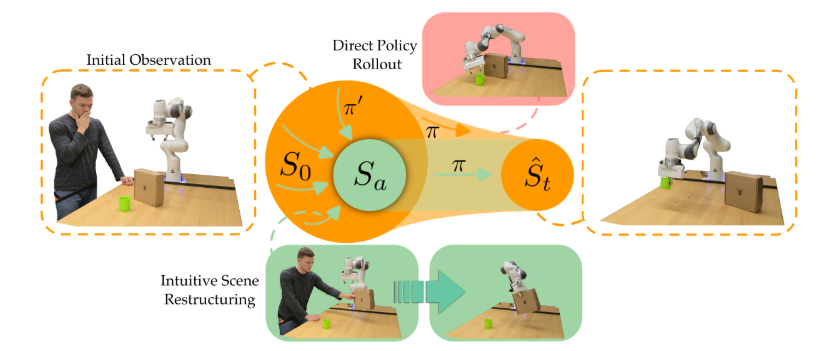
Robot arm learning to grasp a cup. When encountering an out-of-distribution initial observation $S_0$ (e.g., the cup is obstructed by a box), conventional approaches train on large-scale datasets and attempt to directly rollout the robot policy $\pi$. This brute-force approach falls short when the robot encounters unexpected initial environment states. By contrast, ReSET first learns a reduction policy $\pi^\prime$ based on how humans intuitively restructure the scene. This reduction policy rearranges objects (e.g., moving the box out of the way) so that the task is easier to perform and has lower state variance ($S_a$). Our approach then executes the default task policy $\pi$ from this simplified state distribution to reach the goal state $\hat S_t$.
Algorithm and Implementation
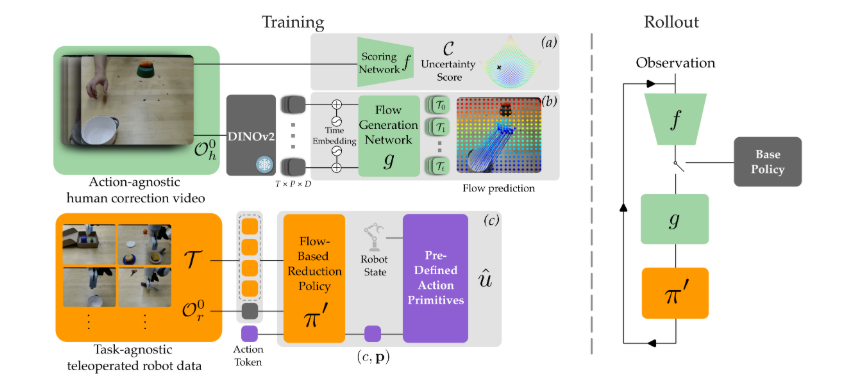
$\textit{Left}$: The model consists of three key components: (a) a scoring network $f$, trained on human videos, which estimates the likelihood that a base policy will succeed under a given initial configuration; (b) a flow generation network $g$, which predicts flows encoding human intuition about how the scene should be restructured into anchor states; and (c) a reduction policy $\pi^{\prime}$ that translates the predicted flows $\mathcal{T}$ into executable robot action primitives $\mathcal{A}$.
$\textit{Right}$: At rollout, the scoring network evaluates the current observation to determine whether it is ready to execute the base policy. If not, the flow generation network produces a flow plan, and the reduction policy will execute that plan. The scoring network then re-evaluates the updated scene before deciding whether to proceed with the base policy.
Real-World Experiments

Coming soon ...
Pick-and-Place